
Groq’s LPU Inference Engine, a dedicated Language Processing Unit, has set a new record in processing efficiency for large language models.
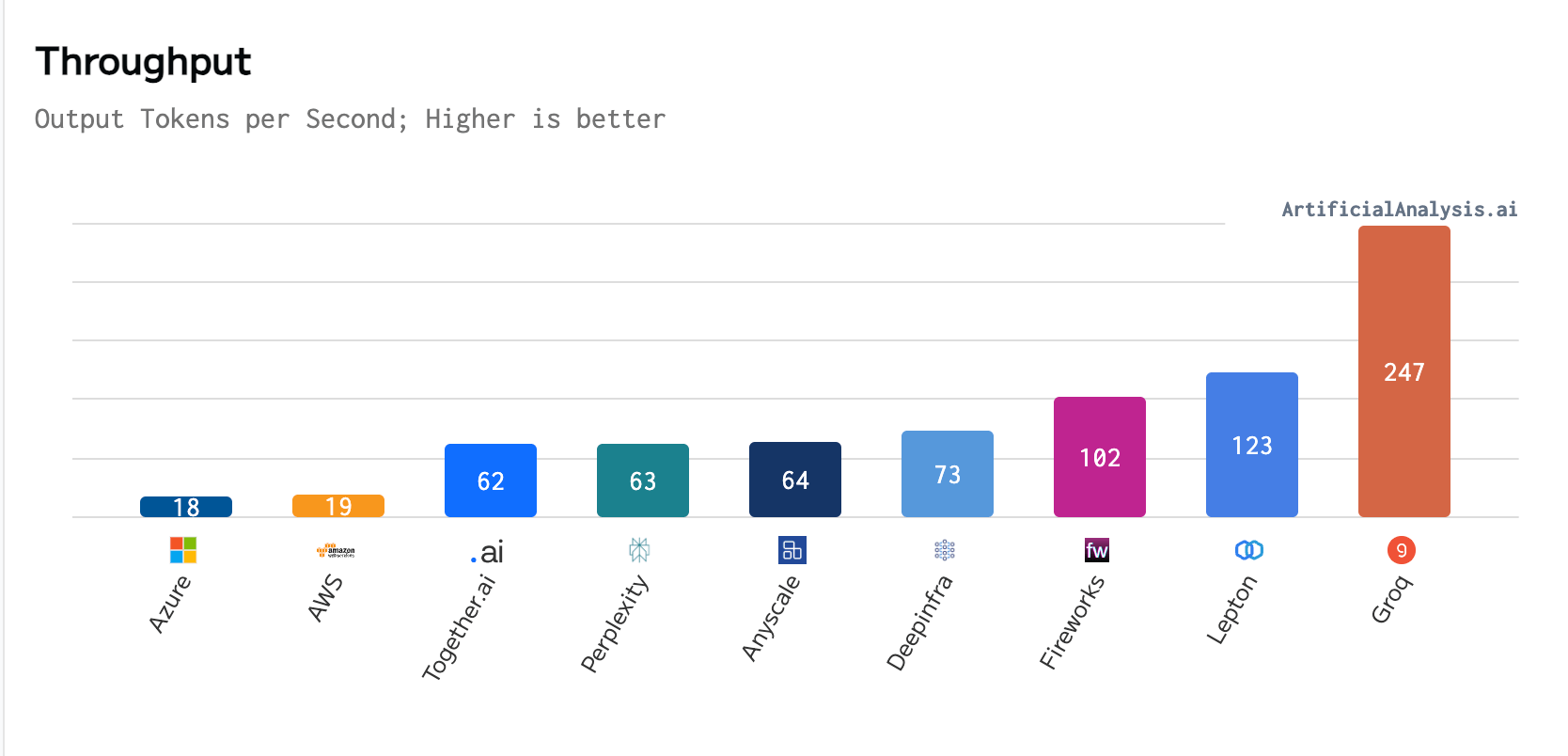
In a recent benchmark conducted by ArtificialAnalysis.ai, Groq outperformed eight other participants across several key performance indicators, including latency vs. throughput and total response time. Groq’s website states that the LPU’s exceptional performance, particularly with Meta AI’s Llama 2-70b model, meant “axes had to be extended to plot Groq on the latency vs. throughput chart.”
Per ArtificialAnalysis.ai, the Groq LPU achieved a throughput of 241 tokens per second, significantly surpassing the capabilities of other hosting providers. This level of performance is double the speed of competing solutions and potentially opens up new possibilities for large language models across various domains. Groq’s internal benchmarks further emphasized this achievement, claiming to reach 300 tokens per second, a speed that legacy solutions and incumbent providers have yet to come close to.
The GroqCard™ Accelerator, priced at $19,948 and readily available
Go to Source to See Full Article
Author: Liam ‘Akiba’ Wright
Tip BTC Newswire with Cryptocurrency
Donate Bitcoin to BTC Newswire

Donate Bitcoin Cash to BTC Newswire

Donate Ethereum to BTC Newswire

Donate Litecoin to BTC Newswire

Donate Monero to BTC Newswire

Donate ZCash to BTC Newswire






